


This article provides an in-depth comparison of popular stream processing systems, including Apache Flink, RisingWave, Spark Streaming, ksqlDB, and more. We hope this article will be helpful for you in making technical decisions.
Introduction
The big data wave has been going strong for over a decade, but the field of stream processing has remained relatively low-key. That is, until the last couple of years, with Confluent (the commercial company behind Kafka) going public, and companies like Snowflake and Databricks investing heavily in streaming. Emerging startups like Decodable and Immerok have also entered the scene. The 2023 SIGMOD Systems Award was given to Apache Flink, the golden age of stream processing finally seems to come.
Today, let's dive deep into the realm of stream processing technology from a technical view. While there are many common concepts such as time windows and watermarks, each system has unique designs when it comes to implementation. The diversity in system design echoes the diverse application scenarios of stream processing, rather than a simple one-size-fits-all solution.
This article provides an in-depth comparison of popular stream processing systems, including Apache Flink, RisingWave, Spark Streaming, ksqlDB, and more. We hope this article will be helpful for you in making technical decisions.
Apache Flink
From its inception, Flink proposed the concept of "unified batch and stream processing", treating batch processing as a special case of stream processing. In essence, batch and stream processing deal with bounded and unbounded data streams respectively. While the vision of unified processing may not be fully accepted by the market, Flink has indeed become the most popular open-source stream processing framework, thanks to its excellent design.
Like many big data frameworks, Flink runs on top of the JVM. Flink's programming interface is known as the DataStream API. Additionally, there's a batch processing interface called the DataSet API. On top of these interfaces, the relational Table API is built for convenient handling of structured data aka. Flink SQL. These interfaces share the underlying runtime, scheduling, and data transmission layers.

The runtime component is similar to common MPP (Massively Parallel Processing) systems: operators are organized in a directed acyclic graph (DAG) and data is exchanged through local and network channels for parallel processing. Most systems in this article follow a similar pattern, and we won't elaborate further on these commonalities.
In contrast to many batch processing systems that favour columnar structures, Flink uses an in-memory representation in a row-based format. This means that each single event (or message) is treated as the unit for computation and serialization during transmission. To speed up execution, Flink SQL employs code generation to dynamically generate and compile operator code, ensuring efficient computation. On the other hand, the DataStream API relies on the JVM's JIT (Just-In-Time) compilation for optimizing user code.
State Management
Flink was the first stream processing system to introduce a state, considering stateful operators as first-class citizens. It's now well understood that lots of common operators in streaming, such as joins and aggregations, require state. State management is a crucial component in streaming, directly influencing the design of fault recovery and consistency semantics.
Flink's operator state is stored in local RocksDB instances (our discussion pertains to the open-source version of Flink). The LSM-Tree structure of RocksDB makes it easy to obtain an incremental snapshot, as many SST files in the current version overlap with those from the previous version. Therefore, when copying the latest snapshot, only the changed parts need to be copied. Flink takes advantage of this to perform state checkpoints, ultimately saving the global checkpoint on persistent storage (e.g., HDFS or S3).
Generalized incremental checkpoints have been introduced since Flink 1.15, which independently implement incremental checkpoints without RocksDB. Readers who are interested can read the official blog.
The key to correct checkpointing lies in achieving globally consistent checkpoints. Flink achieves this by employing the Chandy-Lamport algorithm, which I believe is one of Flink's major design highlights. Specifically, special messages called barriers are injected from the source of the data stream. These barriers flow through the entire DAG along with other messages. Each time a stateful operator is passed, it triggers the corresponding operator's checkpoint operation. When the barrier completes its journey through the entire DAG, all the previous checkpoints contribute to forming a globally consistent checkpoint.
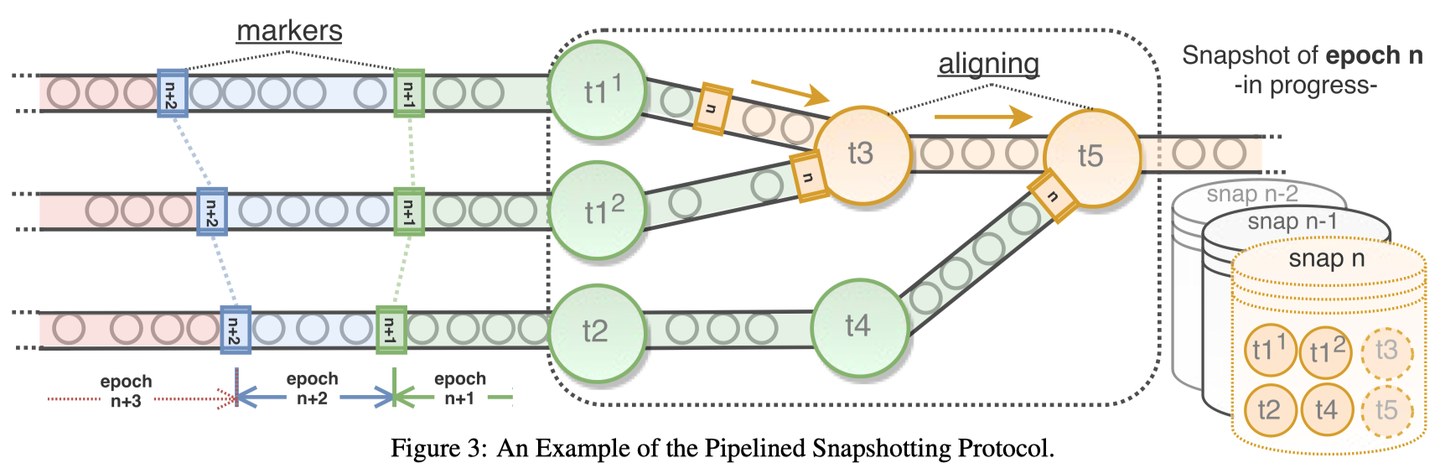
Barriers align when encountering multi-input or multi-output operators, which is crucial for ensuring global consistency and introduces the only overhead it brings. Considering that even without barriers, most streaming tasks inevitably require alignment (e.g., windowed calculations), this cost is not significant. Overall, Flink elegantly tackles consistency checkpoints.

Based on the checkpoint mechanism described above, both at-least-once and exactly-once delivery are easily achievable. For example, for replayable sources (e.g., Kafka) and idempotent sinks (e.g., Redis), all that needs to be done is to include the current Kafka consumption offset as part of the checkpoint state, ensuring exactly-once delivery with ease. For more complex scenarios, some sinks allow achieving exactly once through two-phase commits (2PC) in collaboration with external systems.
RisingWave
RisingWave is a burgeoning open-source stream processing project and is also the project I am currently working on. It positions itself as a streaming database rather than a general-purpose stream processing framework. Users can define streaming tasks in the form of materialized views using SQL, with the goal of making stream processing as simple and accessible as possible. RisingWave does not provide a programming API, but custom code can be introduced via User-Defined Functions (UDFs) if necessary.
RisingWave is written in Rust. In addition to the well-known advantages of Rust, such as memory safety and concurrency support, Rust's built-in async support and rich third-party libraries greatly assist in efficiently handling I/O-intensive scenarios like stream processing. RisingWave's streaming tasks consist of numerous independent actors, which can be thought of as coroutines efficiently scheduled by user-space runtime (tokio). This allows for efficient implementation of operators using high-performance single-threaded in-memory data structures, such as the hash tables used in Hash Join.

In addition to stream processing, RisingWave provides query capabilities similar to a database and guarantees the correctness of snapshot reads. In particular, as long as the query of materialized views is performed within a single transaction, the result will always be consistent with the result of executing the defining SQL. This greatly simplifies the verification of the correctness of streaming tasks for users.
State Management
The aforementioned read consistency guarantee and its internal checkpoint mechanism are closely related. RisingWave employs a global consistent checkpoint mechanism similar to Flink, but with a much higher frequency, defaulting to once every 1 second (as comparison, Flink defaults to 30 minutes). User read requests apply on these checkpoints, ensuring consistent results.
In terms of storage, RisingWave does not directly use open-source components like RocksDB. Instead, it has built its own storage engine based on LSM-Tree and shared storage. The primary motivation behind this choice is to enable lightweight scaling of compute nodes, eliminating the need to download RocksDB's files to new nodes as Flink does. Additionally, RisingWave aims to better leverage the advantages of cloud object storage, such as the low cost and high reliability of S3. RisingWave's built-in storage engine enables database-like serving query capabilities, setting it apart from other systems.
It's worth noting that Flink later introduced Table Store (Paimon) to fill the gap of lacking built-in table storage. However, Table Store mainly uses a columnar structure, making it more suitable for analytical queries. In contrast, RisingWave's storage engine uses a row-based structure, making it more suitable for point queries such as serving queries from Web applications.
Spark Streaming
Apache Spark was originally designed as a batch-processing engine. Thanks to the design of Resilient Distributed Datasets (RDDs), Spark outperforms Hadoop MapReduce.
Spark Streaming uses a technology called D-Streams (Discretized Streams) based on RDD. Unlike other stream processing frameworks that have long-running instances of operators, Spark Streaming divides the stream data into a series of short, stateless, deterministic micro-batches for stream processing.
Spark 2.x introduced a new mode similar to Continuous Processing Mode, but it doesn't seem to be widely adopted, so we won't discuss it here.
The following two figures describe how Spark implements micro-batch stream processing using RDDs. For stateless computations, such as map, there is no difference from batch processing. For stateful computations, such as aggregation, state transitions can be seen as iterations of RDDs, similar to the counts RDD in the rightmost part of the right diagram, which has its ancestors (lineage) consisting of upstream calculations and its own previous version of RDD.

D-Stream Processing Model: (left) For each time interval, generate a corresponding computation graph based on RDDs. (right) For stateful operators, their ancestors also include RDDs from the previous time interval.
Spark Streaming cleverly transforms stream processing into batch processing based on RDDs, effectively reusing RDD's fault tolerance mechanism. In case of a node failure and lost RDD partitions, Spark Streaming simply recomputes the missing RDD partitions. However, there is an evident drawback: the lineage of DStream RDDs keeps growing, leading to increasingly higher recovery costs, not to mention that replayable sources often have retention limitations. Spark Streaming addresses this issue by periodically calling the checkpoint() function of DStream RDDs to persist them, effectively truncating the lineage.
In practice, the micro-batch approach can achieve latencies ranging from seconds to minutes. The authors of the book "Streaming Systems" also acknowledge that, in most cases, such latency meets the requirements and, at most, is "a minor complaint." However, it's worth noting that DStream is essentially a crude imitation of stateful operators, and while it keeps the design simple, it requires higher costs to achieve the same computational performance.
Google Dataflow (WindMill)
Google Dataflow, or its open-source counterpart Apache Beam, is essentially a unified programming interface that supports various backend runtimes, including Apache Flink and Spark, among others. Here, we'll explore Google's in-house WindMill engine. It's better known by its original name, MillWheel, and my knowledge is primarily based on the VLDB'13 paper.
MillWheel completely decouples computation from state management. User-defined operators interact with persistent state stored in a Key-Value model (originally in BigTable) through the State API. MillWheel does not employ a global checkpoint mechanism. Instead, before emitting data downstream, each operator must write its state to persistent storage, similar to the Write-Ahead Logging (WAL) used in databases. This approach keeps the operators themselves stateless and allows for easy fault recovery and scheduling. However, its cost is significant as all state reads and writes require RPCs.
MillWheel's user code only needs to implement the ProcessRecord interface and can save state through the State API.

The lack of a global consistent checkpoint mechanism presents challenges for achieving exactly-once delivery. Unless the operator logic is idempotent, operators need to deduplicate input to prevent processing duplicate messages during crash recovery. This requires storing a message log on external storage for a certain period, incurring a lot of unnecessary RPC costs.
Apache Kafka (ksqlDB)
Kafka is undoubtedly the biggest player in the streaming market. It introduced durability to the middleware domain, laying the foundation for stream processing and, especially, exactly-once delivery. However, it is discussed last here because it’s mostly a message broker, but with very limited capabilities in computation.
ksqlDB (formerly known as KSQL) is a stream processing engine built on top of Kafka, developed by Confluent. ksqlDB expands on the concept of stream-table duality and introduces concepts like materialized views, allowing users to define stream processing tasks using SQL. While this might seem promising, ksqlDB has various limitations and compromises in its design, which may be due to its lightweight plugin-oriented approach, leading many users to seek alternative solutions for complex use cases.
ksqlDB's treatment of state is an example of such compromise. ksqlDB uses Kafka topics to store state changelogs and materializes these changelogs into tables with the help of RocksDB, enabling efficient queries by operators - remember stream-table duality? However, this approach results in ksqlDB consuming several times more resources for the same size of state, and it can inadvertently lead to data inconsistency issues.
Additionally, since ksqlDB tasks always run on a single Kafka node without support for data shuffling, users must carefully ensure that data is distributed correctly for aggregation and join operations. When necessary, extra repartitioning topics must be created manually. This limitation constrains ksqlDB's ability to handle complex SQL queries.
Others
The following systems are no longer as popular as they once were, but their design philosophies and trade-offs are still worth studying.
Flume/FlumeJava: Originally developed by Google, Flume is one of the earliest stream processing systems, dating back to 2007. It was initially designed as a programming framework for convenient stream processing and was later used to implement MillWheel. Its core is a data model called PCollection, which is an immutable, ordered, and repeatable data collection, similar to Spark's RDD. PTransform defines how to transform PCollection. Flume does not have built-in state management, and users need to implement it themselves using external databases.
Apache Storm: Open-sourced by Twitter, Storm is another early stream processing system. Its core data model is called Tuple, similar to PCollection. Unlike other systems that strive for exactly-once delivery, Storm prioritizes faster performance over consistency guarantees. It only supports at least once semantics, making its implementation relatively simple and efficient. Unsurprisingly, Storm does not have built-in state management, and users must implement it using external databases.
Materialize: Materialize is perhaps the earliest product to propose the concept of streaming database. Similar to RisingWave, it only provides a SQL interface, allowing users to define tables and materialized views. Materialize is developed based on a Differential Dataflow, which does various transformations on Collections to form data streams. The operator's state is saved in an in-memory Arrangement structure. This design makes it effectively a single-node in-memory database, limiting the scale of data it can handle. It also lacks checkpointing support and replies on replaying events from source to recover from failure.
Conclusion
